
똑같은 삽질은 2번 하지 말자
SPA에서 어떻게 페이지의 이동이 이루어질까? (hash mode, history mode) 본문
개요
vue router의 hash mode와 history mode에 대해 공부하는데 애초에 어떻게 페이지의 로드없이 페이지의 이동이 이루어지는가에 대해 궁금해져서 작성하는 글
hash mode의 페이지 이동
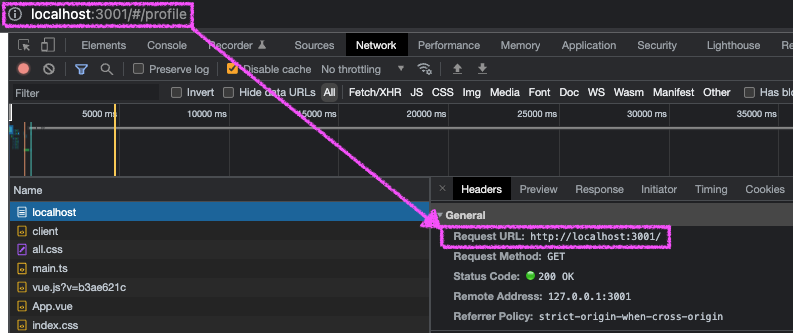
이하의 이미지를 보면 uri에 /#/ 이라는 특별한 친구가 들어가는데 #의 이후의 변경에 대해서는 웹서버에서는 인식못한다.
왜냐하면 request URL로써는 #을 포함해 # 이후의 부분들은 생략되어 요청이 날라가기 때문이다.
요청이 날라가는건 최초에 한번 or 직접접속 or 새로고침 이고 이후에 #의 뒷부분들의 바뀌어도 HTTP Request가 발생안한다.
HTTP Request가 발생하지 않으므로 페이지의 로드없이 URL이 바뀐다.
그럼 페이지 이동은?
https://developer.mozilla.org/en-US/docs/web/api/window/hashchange_event
Window: hashchange event - Web APIs | MDN
The hashchange event is fired when the fragment identifier of the URL has changed (the part of the URL beginning with and following the # symbol).
developer.mozilla.org
URL에서 #은 hash라고 불리어지며 그 해쉬가 변경되는걸 감지해주는 web api가 있다.
위의 기능을 이용해 해쉬가 변경되는걸 vue-router는 감지해서 새로운 페이지로 페이지의 갱신없이 랜더링하는게 가능한 것이다.
history mode의 페이지 이동
history mode로 바꾸면 url이 우리가 평소에 보던 url처럼 /#가 제거되서 이쁘게 나온다.
물론 이렇게 되면 웹서버에서는 url이 바뀌는걸로 감지해 request가 날라가 페이지의 로드가 이루어 지는걸로 생각되는데
실제로 vue의 history mode로 바꾸어도 request가 날라가지 않는다는걸 볼 수 있다.
공식문서의 글을 보면

pushState라는 History API를 이용해 브라우저의 상단의 URL을 바꾸면서 내부적으로는 request를 날리지 않고
페이지의 이동을 하는 그런 흐름으로 이루어지는것 같다.
추가로 히스트리 모드를 사용할 때 주의점이라고 적혀있는 부분인데

#을 제거한 정상적인 URL로 브라우저 상단의 URL창에서 직접 입력해 이동하는 방식(직접 접속)으로 하면
웹서버에 존재하는 route는 / => index.html 밖에 없는데 그 이외의 route의 접근으로 404가 발생할 수 있다는 말이다.
그러므로 모든 요청을 루트요청으로 우회시키면 그 이후, / 이하의 부분들은 클라이언트(브라우저)에서 처리를 하는 방식으로 하면된다.
그럼 hash모드에서 직접접속은 괜찮나?
제일 위의 이미지를 보면 #이후의 부분들은 전부 생략해서 request가 보내지는걸 확인할 수 있다.
그 의미는 따로 우회 셋팅을 안해도 자동으로 다 루트요청으로 날라간다는것이다.
여담으로 vue를 쓰는 사람들이 히스토리 모드로 하는 이유는 #이 붙은 이 못생긴 URL이 SEO에 나쁜 영향을 미친다는 것 때문이다.